

Trusted by Market Leaders











Why Common Access Architectures
Are No Longer Enough

Cloud & Identity are Top Cyber Targets
The majority of attacks are now focused on identity, with theft of credentials or secrets or exploiting human error.

Passwords, Secrets & VPNs Don't Scale
Engineers and security teams' interests are aligned, with both seeking easier, more secure ways to govern access.

Compliance Needs Are Increasing
FedRAMP, HIPAA, SOC 2, SEC disclosure, and more. Customers need to scale how they meet regulatory requirements.


Modern Access for Today's Needs
Teleport provides on-demand, least-privileged access to your infrastructure, on a foundation of cryptographic identity and zero trust, with built-in identity and policy governance

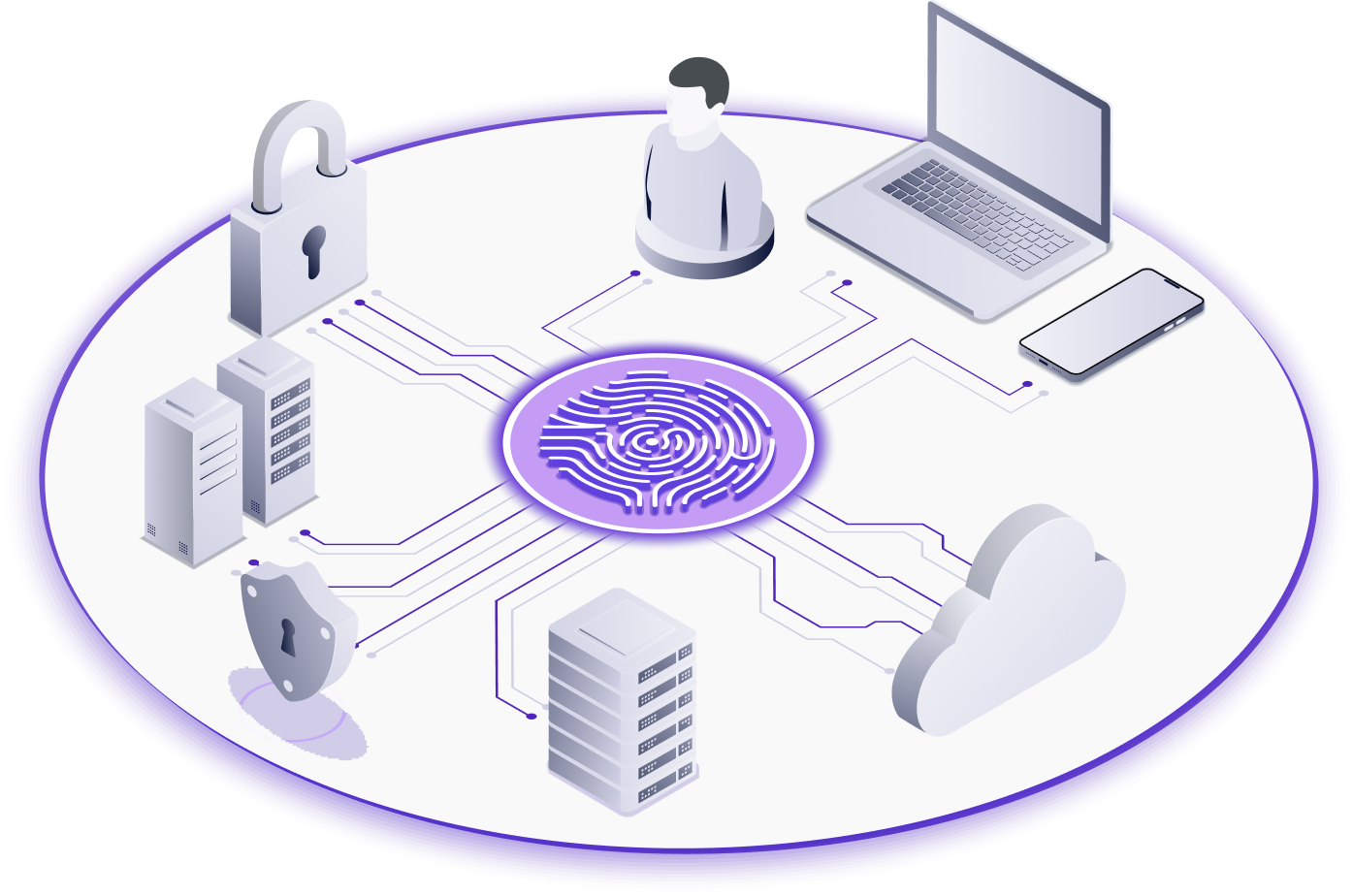
Cryptographic Identity
For all users, machines, devices, resources
Zero Trust Access
To applications and workloads, with secure remote access

Secretless Authentication & Ephemeral Privileges
For on-demand and just-in-time access, with fine-grained audit

Identity & Policy Governance
Instant access views and remediation across all infrastructure
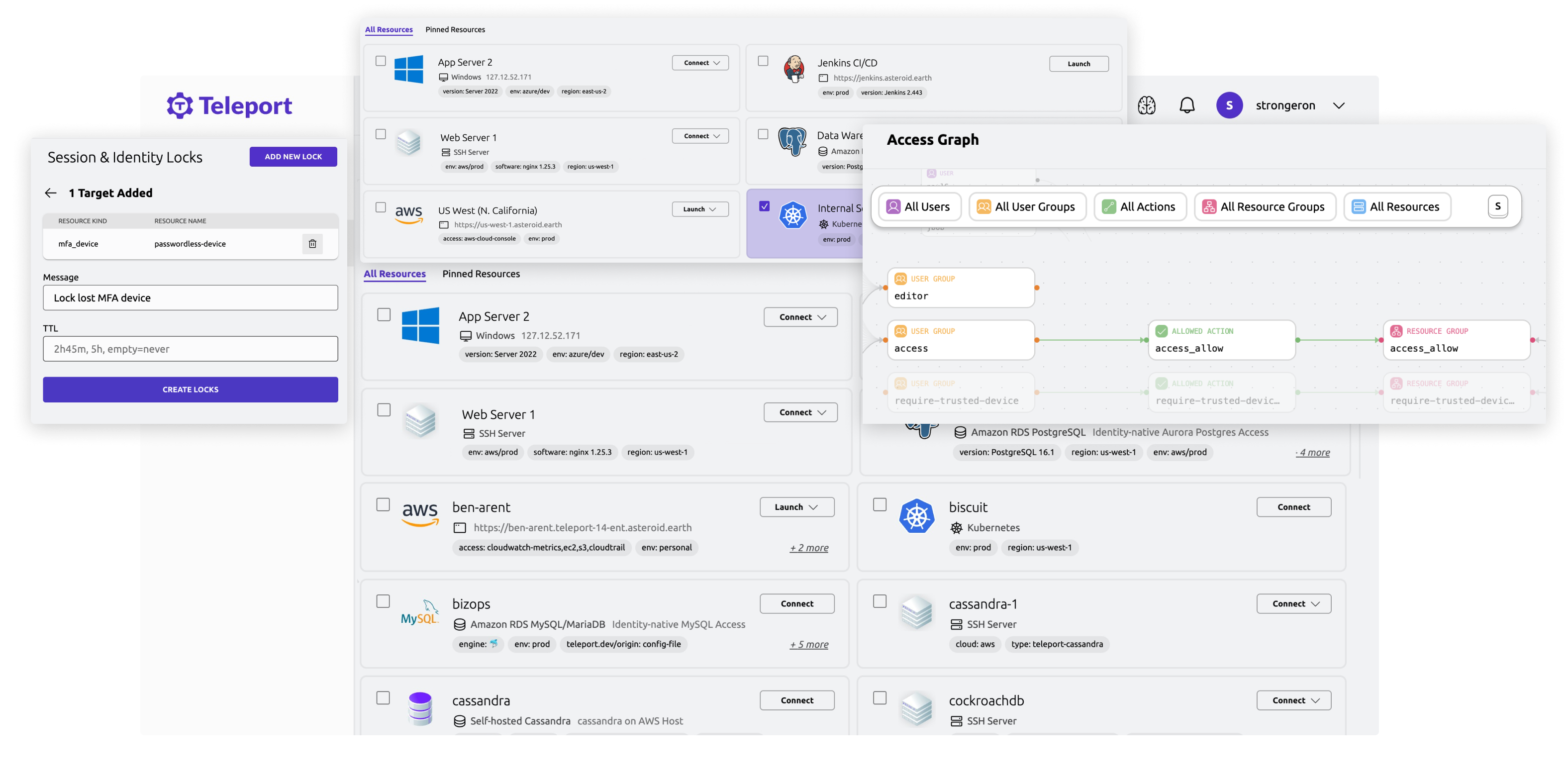
A Unified Experience that Breaks Access Silos
We secure user and machine access to all services, apps and workloads in your clouds and data centers.









Problems Customers Solve with Teleport

Improve Engineer & Workforce Productivity
- Improve onboarding and offboarding
- Eliminate access silos
- Adopt on-demand and just-in-time access
- Eliminate VPNs and bastion hosts
- Unify user and machine access

Protect Infrastructure from Identity Attacks
- Eliminate credentials & standing privileges
- Eliminate backdoor access paths
- Monitor access patterns and respond
- Apply policy/remediate instantly across all infrastructure

Meet Compliance Requirements
- FedRAMP
- SOC 2
- HIPAA
- PCI
- ISO 27001

What Makes Teleport Unique
A message from CEO Ev Kontsevoy
