Teleport Blog - AWS: Rolling your own servers with K8s, Part 2 - May 14, 2019
AWS: Rolling your own servers with K8s, Part 2
Networking for Bare Metal Kubernetes Cluster
Introduction
This is the second part of the three-part series of blog posts for people who, for reasons only known to them, need to leave AWS and move their workloads into a colocation facility, using Kubernetes to provide "cloudiness" of operations that we're all so accustomed to.
In the first part, called AWS vs Colocation, we covered some hardware considerations and compared the costs of AWS and the colo, and here we will dive into building a network for a small bare metal environment to run Kubernetes on.

Networking
Networking is by far the most complicated topic here. We decided to only focus on using a simple network without hardware redundancy to contain the scope of the discussion.
For our setup, we want to build a network that works really well with Kubernetes, is easy to set up and manage, and provides all basic features we'd expect coming from a typical cloud environment.
Networks get progressively more complex as the size of your infrastructure grows. The reason for this is that the network technology hasn’t been advancing as quickly as CPUs or virtualized and containerized workloads. In good old days, we had maybe 100-200 CPU cores in a rack, each with a handful of IP addresses. Now it's possible to cram thousands of CPU cores into a single cabinet where a single core may run several containers that demand their own IP addresses or even private LANs. Multiply that by the number of cabinets and suddenly you are hitting all kinds of legacy network limitations. If you are thinking about running containers at this scale, forget about legacy nonsense like VLANs and be aware of the software-defined networking (SDN) revolution in the making. Familiarize yourself with new concepts like SDN controllers and white box switches.
But for our purposes, a traditional combination of a router with a switch-per-LAN should suffice, either as separate devices or something that combines all three. A colocation provider will probably route a small subnet into your cabinet, something like /27 i.e. you’ll have 30 usable public IP addresses (sans two addresses for the router and for broadcast).
Next, you will need to create private LANs for your environment. Having separate LANs helps with both security and performance.
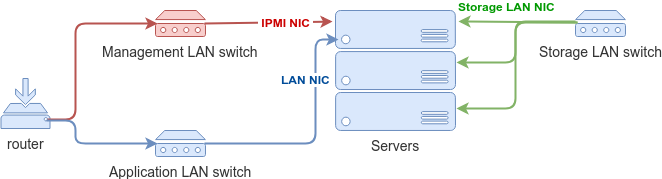
- Management LAN. This network will be used to remotely manage hardware, i.e. physical servers via IPMI, switches, etc. Often this is the LAN you may want to have a VPN configured for.
- Storage LAN for enabling network-based storage volumes. As your needs for CPU power and storage grow, these resources have very different scaling costs and characteristics. Not having to rely on host-local storage from the beginning allows for more flexibility in scaling storage separately from everything else. This is why I recommended having a separate storage NIC on every server and having a dedicated storage LAN switch also helps with performance.
- Application LAN for your applications. You may need to create private LANs for separate applications, similar to AWS VPCs, but it’s easier to do later in software.
Obviously, each of your LANs should have its own non-overlapping address space. It does not hurt to configure a DHCP server per LAN.
You may ask: what about ZeroTrust security? The wonderful idea that we should not be using LAN segregation for protection and instead secure every host as if it was exposed to the open Internet. Zero Trust is a solid approach when designing your software security, i.e. it is relevant when you have full control over the systems you’re protecting. But you shouldn't be trusting a closed source implementation of server management software (which came from a hardware vendor) to be accessible from the Internet. Therefore have your IPMI interfaces behind a VPN. Besides, this setup does not preclude you from using zero trust software, like our open source ZeroTrust SSH and Kubernetes gateway that enables SSH and Kubernetes API access between multiple data centers and do not rely on secure private keys (i.e. not vulnerable to private keys leaked via stolen laptops, etc).
When deploying Kubernetes into a simple network like this, the first question that will come up will likely be the need for floating public and private IPs, i.e. how an application can request LAN addresses for its internal services and public IP addresses for the public services.
- Private LAN networking in Kubernetes can be done in two ways: using the host network or using an internal virtual SDN. Ideally, your applications can run with the native host network. This dramatically simplifies your network architecture and makes everything much easier to grok. The common reasons NOT to use host networking include the need to run multiple conflicting network services on the same host, more flexible network security options and greater programmer’s control via Kubernetes API.
- Public IP space for your cluster can be managed by Kubernetes itself via MetalLB, just feed it the public IP block you have received from your colocation provider and Kubernetes will be able to provision floating public IPs and load balancers for your application just like how you’re used to it on AWS.
Capacity
Building a network for an environment this small seems is pretty straightforward assuming you understand how much bandwidth and resilience you really need.
I.e. for workloads that are latency sensitive at the flash / memory level, congestion on a link will start to matter at levels of 30 - 50% of capacity. Congestion on things that operate more at the speed of disks or cross-internet traffic won't likely start to matter until closer to 80% utilization.
And it's really nice to have enough bandwidth and the right network design to not have to think so much about locality. If your software engineers can assume that it doesn't matter where the resource is in a datacenter facility (on the basis of bandwidth or latency), it makes their lives much easier.
Teleport cybersecurity blog posts and tech news
Every other week we'll send a newsletter with the latest cybersecurity news and Teleport updates.
Management
Most colocation providers offer services to provision, i.e. physically rackmount your equipment and turn it on for you. But when it comes to remote management, for folks who have not dealt with bare metal servers, it will not feel too different from virtualized solutions.
Once your servers are up and running, you’ll be able to manage them via a built-in management interface. IPMI is an open standard, but there are proprietary solutions with similar capabilities like iDRAC from Dell. The server management software runs on a board management controller (BMC) which is basically just another computer which runs even when your server’s power is turned off. Modern BMCs offer an HTML5 UI as well as an API to manage servers remotely. You can turn the power on and off, have remote access to a built-in VGA display, a keyboard, monitoring, and alerts, and you can remotely mount an installation media for the operating system. If you decide to run consumer grade hardware in your data center, keep in mind that most consumer motherboards lack remote management features but a KVM-over-IP can offer most of the same features.
Conclusion
In this post, we've covered a simple network setup that is sufficient to run Kubernetes and popular software projects for network-attached storage like Ceph or clustered filesystems. That's as close to EBS as you can get.
In the next post scheduled for next week, we are going to be looking into utilizing Kubernetes for cloud-like operations, comparing Kubernetes on bare metal vs virtualization and more.
Thanks to Aaron Sullivan and Erik Carlin for reading the draft of this post and providing valuable suggestions.
Tags
Teleport Newsletter
Stay up-to-date with the newest Teleport releases by subscribing to our monthly updates.


Subscribe to our newsletter
